How to Use AI Gateway (LiteLLM): Unified Management of AI Large Language Models
Table of Contents
What is LiteLLM Gateway Server? #
LiteLLM is an open-source unified interface tool designed to simplify interactions with various large language models (such as OpenAI, Anthropic, Google, etc.). Acting as a proxy layer, it provides standardized API interfaces, helping enterprises centrally manage access to multiple AI service providers, monitor usage, control costs, and simplify technical integration. LiteLLM is particularly suitable for enterprise environments that need to use multiple LLM services simultaneously, significantly reducing management complexity and improving security.
Enterprise Pain Points #
In today’s era of rapid development of AI large language models (LLMs), enterprises face numerous challenges:
Multi-vendor Management Dilemma
- Different AI service providers (such as OpenAI, Anthropic, Google, etc.) require different API keys
- Each vendor has independent billing systems and usage statistics
- Teams need to manage multiple platform accounts and keys
Cost Control Challenges
- Difficulty in tracking actual API usage across different teams
- Lack of unified cost accounting and budget management
- Inability to effectively monitor and optimize API call costs
Technical Integration Complexity
- Different vendors have varying API interface formats
- Need to maintain separate integration code for each vendor
- Inconsistent model parameters and calling methods
Security and Compliance Challenges
- Scattered API key storage increases security risks
- Difficulty in implementing unified access control and permission management
- Lack of complete audit logs and compliance records
Quick Start #
1. Environment Preparation #
Before starting, ensure your system meets the following requirements:
- Docker and Docker Compose are installed
- Required API keys are obtained (such as OpenRouter API Key or OpenAI Key)
2. Installation Steps #
mkdir litellm-server
cd litellm-server
echo 'LITELLM_MASTER_KEY="sk-1234"' > .env
echo 'LITELLM_SALT_KEY="sk-1234"' > .env
source .env
2. Configure LiteLLM #
vi config.yaml
model_list:
- model_name: gpt-4o-mini
litellm_params:
model: gpt-4o-mini
api_key: os.environ/OPENROUTER_API_KEY
api_base: https://openrouter.ai/api/v1
- model_name: "gpt-4o"
litellm_params:
model: "openrouter/openai/gpt-4o"
api_base: "https://openrouter.ai/api/v1"
api_key: "os.environ/OPENROUTER_API_KEY"
general_settings:
store_model_in_db: true
store_prompts_in_spend_logs: true
3. Configure Docker Compose #
version: "3.11"
services:
litellm:
build:
context: .
args:
target: runtime
image: ghcr.io/berriai/litellm:main-stable
#########################################
## Uncomment these lines to start proxy with a config.yaml file ##
volumes:
- ./config.yaml:/app/config.yaml #<<- this is missing in the docker-compose file currently
command:
- "--config=/app/config.yaml"
##############################################
ports:
- "4000:4000" # Map the container port to the host, change the host port if necessary
environment:
DATABASE_URL: "postgresql://llmproxy:dbpassword9090@db:5432/litellm"
STORE_MODEL_IN_DB: "True" # allows adding models to proxy via UI
env_file:
- .env # Load local .env file
depends_on:
- db # Indicates that this service depends on the 'db' service, ensuring 'db' starts first
healthcheck: # Defines the health check configuration for the container
test: [ "CMD", "curl", "-f", "http://localhost:4000/health/liveliness || exit 1" ] # Command to execute for health check
interval: 30s # Perform health check every 30 seconds
timeout: 10s # Health check command times out after 10 seconds
retries: 3 # Retry up to 3 times if health check fails
start_period: 40s # Wait 40 seconds after container start before beginning health checks
db:
image: postgres:16
restart: always
environment:
POSTGRES_DB: litellm
POSTGRES_USER: llmproxy
POSTGRES_PASSWORD: dbpassword9090
ports:
- "54321:5432"
volumes:
- postgres_data:/var/lib/postgresql/data # Persists Postgres data across container restarts
healthcheck:
test: ["CMD-SHELL", "pg_isready -d litellm -U llmproxy"]
interval: 1s
timeout: 5s
retries: 10
prometheus:
image: prom/prometheus
volumes:
- prometheus_data:/prometheus
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9099:9090"
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention.time=15d'
restart: always
volumes:
prometheus_data:
driver: local
postgres_data:
name: litellm_postgres_data # Named volume for Postgres data persistence
4. Start Services #
# Start services
docker-compose up -d
# Check service status
docker-compose ps
# View logs
docker-compose logs -f
5. API Call Example #
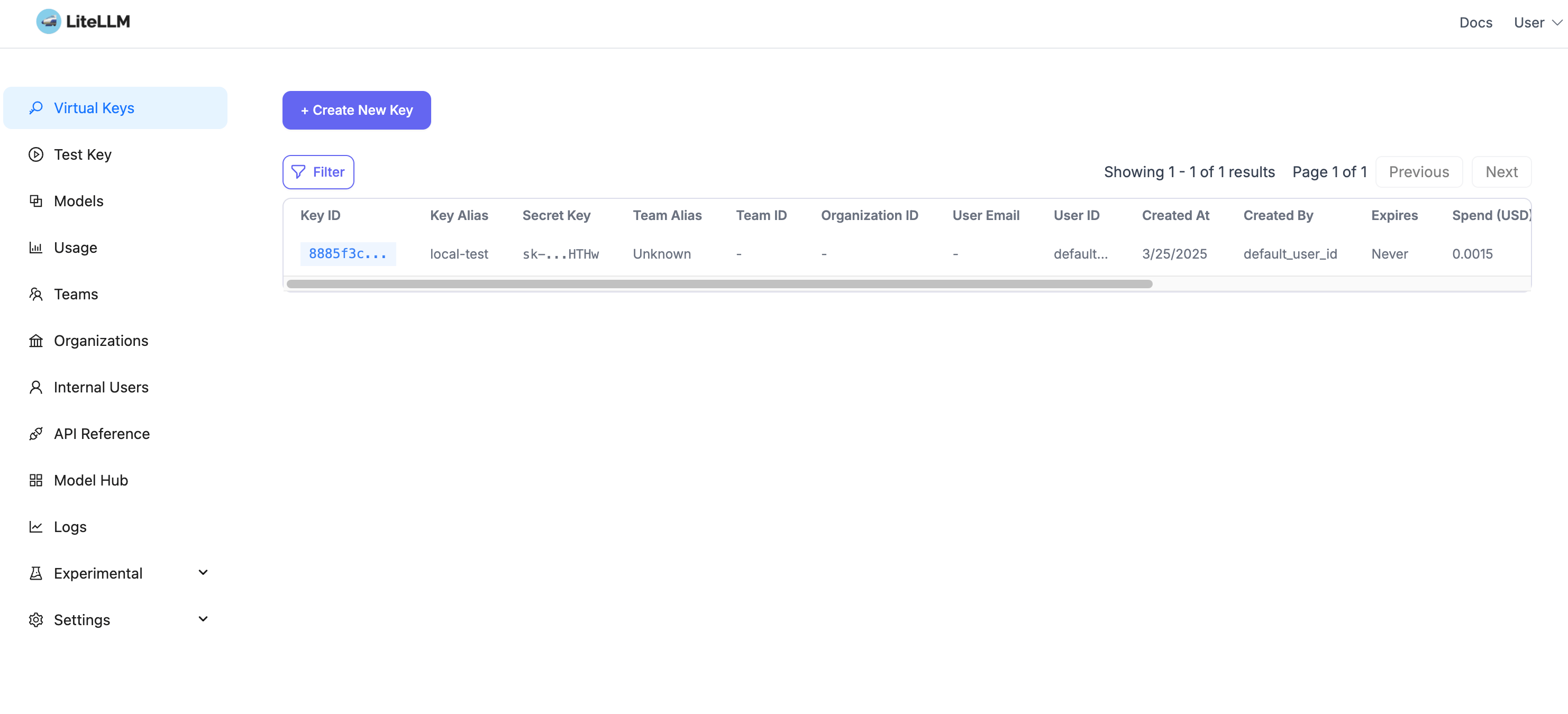
Create virtual key: Visit http://localhost:4000/ui/?userID=default_user_id&page=api-keys
Call example:
export $LITELLM_API_KEY=xxxx
curl http://localhost:4000/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LITELLM_API_KEY" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "system",
"content": "You are an assistant. Your name is Li Si San"
},
{
"role": "user",
"content": "how are you? what your name?"
}
]
}'
6. Management Interface #
Access LiteLLM management interface: http://localhost:4000/ui
Main features:
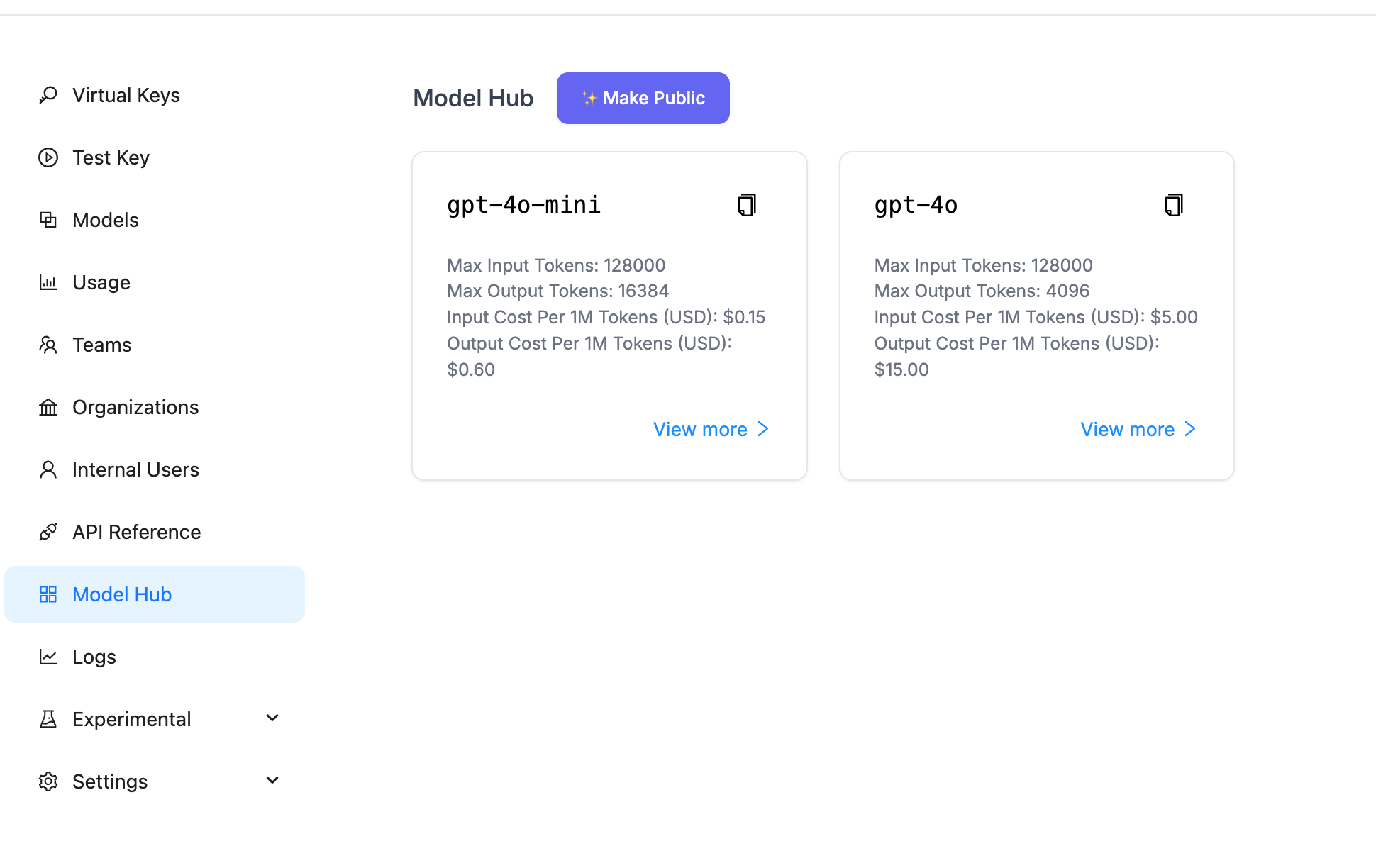
- Model Management: View and configure available models
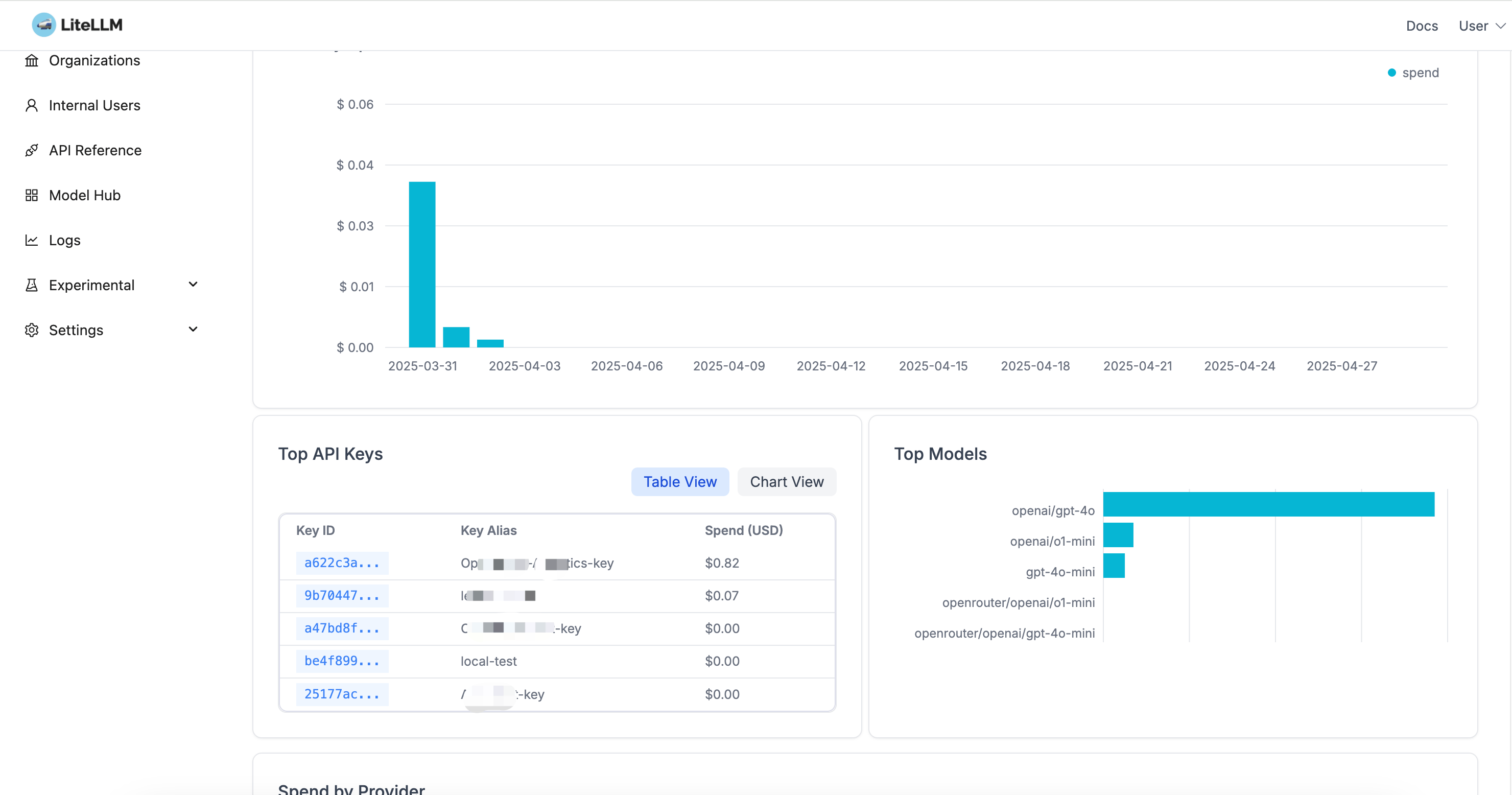
- Usage Statistics: Monitor API calls and costs
- Key Management: Create and manage virtual keys
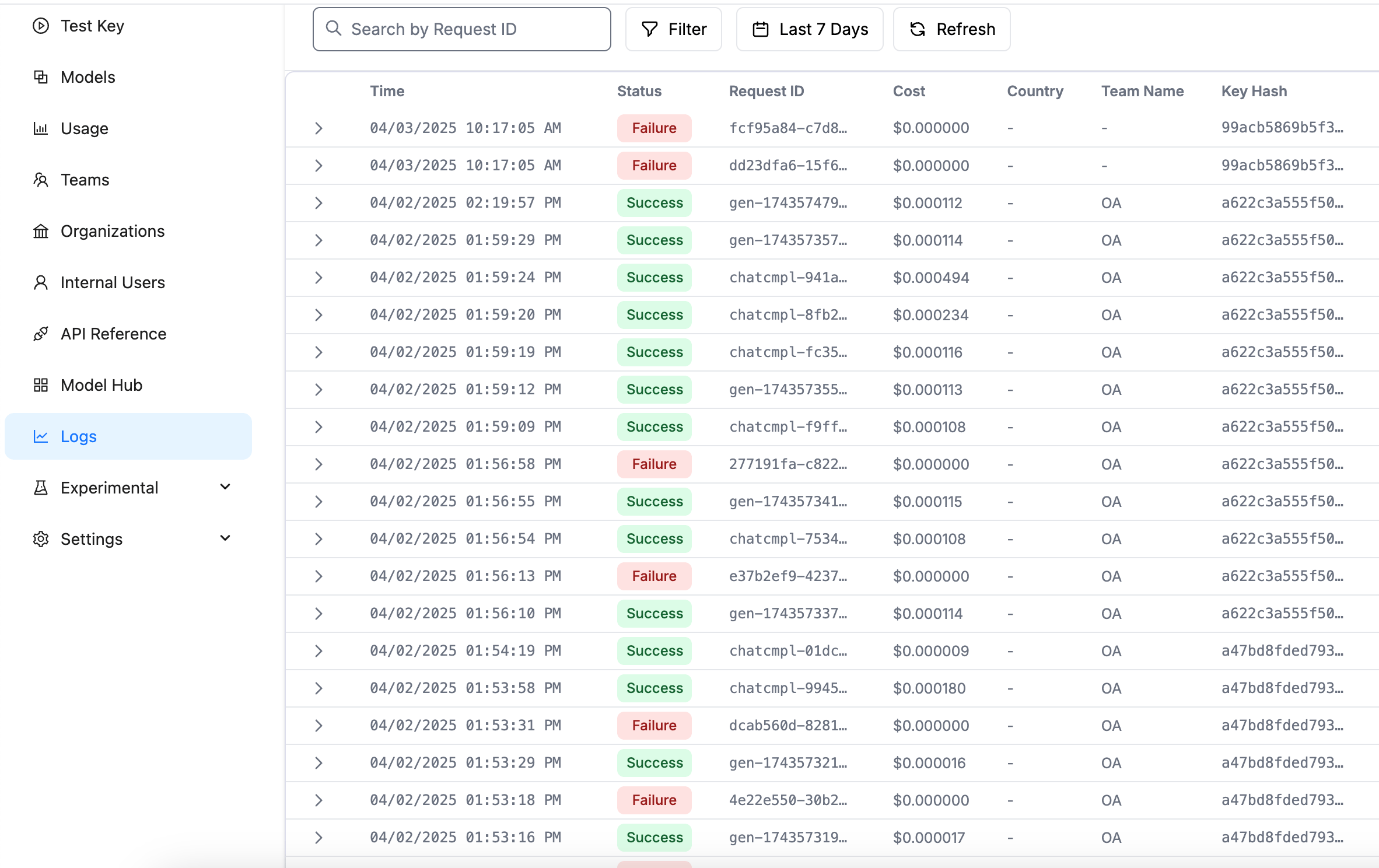
- Log Viewing: View detailed call logs
Interface preview:
Summary #
LiteLLM, as a unified LLM proxy layer, provides enterprises with an elegant solution:
Unified API Interface
- Provides standardized interfaces, simplifying integration work
- Ability to switch between different AI service providers without modifying existing code
- Unified model parameters and calling methods
Centralized Key Management
- Virtual key system protecting original API keys
- Unified key management and rotation mechanism
- Fine-grained access control and permission management
Complete Monitoring and Analysis
- Unified usage statistics and cost analysis
- Detailed call logs and performance monitoring
- Support for multi-team resource allocation and billing
Flexible Deployment Options
- Support for local deployment and cloud services
- Scalable architecture design
- Rich integration options